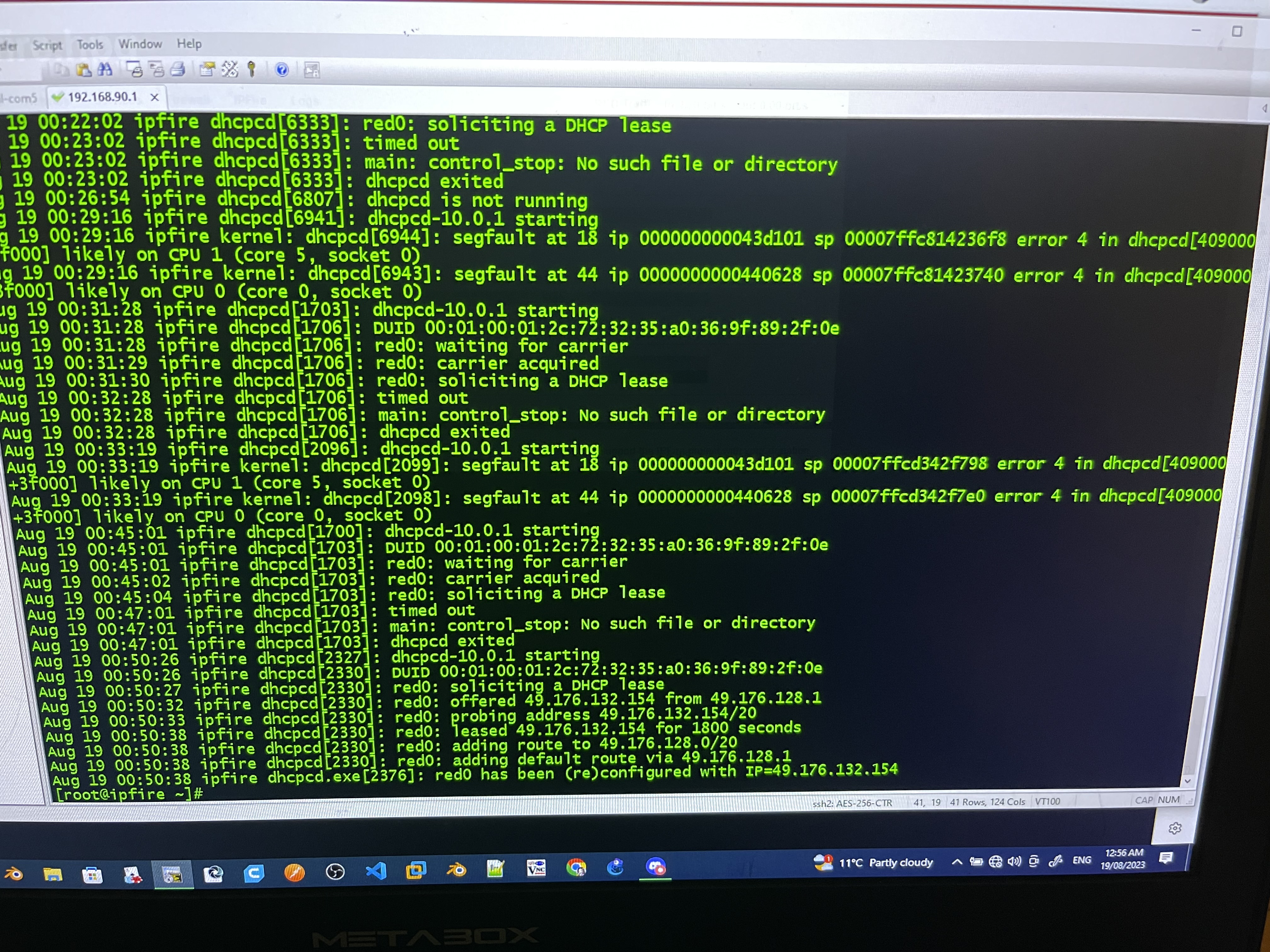
One worrying thing is that you are getting segfaults sometimes when starting dhcpcd. That should not be happening. Could you raise the problem with the upstream dhcpcd team at https://github.com/NetworkConfiguration/dhcpcd/issues
I am not sure if the segfaults would be getting in the way of a working connection but it certainly would not help.
dhcpcd trues to make a connection for 60 seconds. That is usually more than enough.
In your logs you can see that
carrier is acquired
dhcpcd solicits for a DHCP lease
dhcpcd times out.
There is never a response back from your ISP.
I presume that the connection at 00:50:26 is your manual attempt.
There dhcpcd solicits a lease and is offered one back which is then accepted.
From the logs there is no other indication of a difference except for the segfaults with the earlier attempts hence my thought to raise this with the dhcpcd team. It looks to be specific to our setup as you are the first one to raise a problem with dhcpcd-10.0.1
There is a new version out (10.0.2) which might already have a fix although nothing obvious from the Changelog.
Please install TCPDUMP addon and monitor the communication between dhcpcd (the DHCP client daemon) and the DHCP server (provided by your ISP). DHCP uses UDP as its transport protocol. Here’s how you can use tcpdump to monitor DHCP traffic:
tcpdump -i red0 port 67 or port 68 -e -n
port 67 or port 68: Capture traffic on ports 67 and 68, which are used by DHCP.
-e: Display the Ethernet headers.
-n: Do not resolve hostnames (this speeds up the display since DNS lookups aren’t performed).
While monitoring, you should see the DHCP handshake:
DHCP DISCOVER: Sent from the client when trying to discover DHCP servers on the network.
DHCP OFFER: Sent from the server to offer an IP address to the client.
DHCP REQUEST: Sent from the client requesting the offered IP address.
DHCP ACK: Sent from the server acknowledging the IP address assignment.
If you cannot figure it out, please post here the results. Since I use a lot GPT4 to help other users, it would be useful for my research if you post the logs in character form.
If you want to save the tcpdump logs to analyze it with tools like Wireshark, you can use -w filename.
An issue has been raised on the dhcpcd site for segfaults with 10.0.1 when zero length messages were received by dhcpcd.
A fix for that has been released and is in version dhcpcd-10.0.2
I can’t tell if your segfaults are from the same cause as those on the dhcpcd issues list.
Can you look through the messages log for any messages related to segfaults. The section will be kernel so you won’t be able to filter. You will probably have to look in the logs in the time period from 00:33:19 until something like 00:34:00
That should cover the time period when the segfault info should be logged.
I don’t believe so as the segfaults are occurring straight after it says dhcpcd-10.0.1 starting and before any waiting for carrier and carrier acquired etc messages.
If it was due to no reply then, as that can often be a situation that occurs I would expect it to have already been flagged up in the dhcpcd git repo issues.
There are however two different segfault issues that have been raised and fixes for both are in dhcpcd-10.0.2
The kernel messages about the segfault would be the most help, also for the dhcpcd dev team, as dhcpcd is segfaulting but that would then have the trace info etc in the kernel logs.
According to GPT4, error 4 refers to the specific type of segmentation fault. In many cases, an error 4 refers to a “read” fault, meaning the process tried to read a memory location it wasn’t permitted to. Can it be due to a bug elicited when running IPFire kernel (indirect branch tracking involved?), in a container?
me neither, but in my ignorance I consider containers similar to virtualization, and there has been a report here of Indirect Branch Tracking and hypervisor conflicts. The bugs clearly are very different, but access to memory seems to be important in this specific set of circumstances to allow this to be a possibility? Maybe?
EDIT: maybe OP could boot IPFire with ibt=off and see if the segmentation fault goes away
That other issue was a bug in Hyper-V due to a missing instruction at the beginning of the hypercall page. This is still being worked on by the Hyper-V people.
It has been fixed in IPFire by the latest kernel update which has put in a workaround that checks if this required command is present on the hypercall page and if not then it switches off IBT so that the vm boots and runs without IBT.
Interesting to see if this container problem also stops if IBT is turned off.