I am working on the machine, and I hear IpFire start and stop squeaks. When I check the System > Home I discover the time alive is few seconds. Is that an Attack? Its annoying. What is the remedy?
Any entries in the logs ( /var/log/messages )?
Have you direct console access to IPFire? Maybe you can see the reason on the system console ( not SSH ).
1 Like
Hi. Thanks for your reply. IPFire has been off line for several months, and reinstalled with a setup change date/time from west coast US to Caribbean east coast. And a version update. In other words, no logs—although today the unit has also started/stopped. And I have noticed this tendency but never Q community wrote about it. Can /var/log/messages be read without Serial into unit; what is the prompt of the unit for that file? Best regards,
If the restarts occur very often, after very short running times, you should consider to access your system through the console ( serial or keyboard/monitor ). Log in to root, the pw is set in setup whilst installation.
Console access gives system messages not stored in /var/log/messages ( as suddenly occuring memory problems, heat problems, disk problems, … ).
From the console shell you can read system log by less /var/log/messages. for example.
Without a reboot being carried out the usual reason for a disconnect/connect is that the carrier signal has been lost by IPFire, ie a problem with the connection from the ISP.
You can check this by looking in the logs from the WUI menu in Logs - System Logs and then in the dropdown box select RED and then press the Update button and you will get the logs for the date selected.
If you see a message talking about Carrier lost or similar then that is what is causing the problem.
If it is not a Carrier problem then there should be some other message in the logs from dhcpcd when the connection is disconnected and then reconnected.
Make sure that you don’t have a Reconnect action specified in the WUI menu Network - Connection Scheduler. That would also cause a disconnect/reconnect on the period defined in that action.
1 Like
Follows is the RED Update from System. I have the machined turned off at midnight and on at 5am - could the failed to renew be the problem?::
10:15:10 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
10:15:10 dhcpcd[707] : red0: failed to renew DHCP, rebinding
09:22:40 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
09:22:40 dhcpcd[707] : red0: failed to renew DHCP, rebinding
08:30:10 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
08:30:10 dhcpcd[707] : red0: failed to renew DHCP, rebinding
07:37:40 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
07:37:40 dhcpcd[707] : red0: failed to renew DHCP, rebinding
06:45:10 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
06:45:10 dhcpcd[707] : red0: failed to renew DHCP, rebinding
05:52:40 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
05:52:40 dhcpcd[707] : red0: failed to renew DHCP, rebinding
05:00:10 dhcpcd[707] : red0: adding default route via 192.168.0.1
05:00:10 dhcpcd[707] : red0: adding route to 192.168.0.0/24
05:00:10 dhcpcd[707] : red0: leased 192.168.0.14 for 3600 seconds
05:00:05 dhcpcd[707] : red0: probing address 192.168.0.14/24
05:00:05 dhcpcd[707] : red0: offered 192.168.0.14 from 192.168.0.1
05:00:05 dhcpcd[707] : red0: soliciting a DHCP lease
05:00:04 dhcpcd[707] : red0: IAID b9:53:e8:35
05:00:04 dhcpcd[707] : red0: carrier acquired
05:00:02 dhcpcd[707] : red0: waiting for carrier
05:00:01 dhcpcd[707] : DUID 00:01:00:01:2a:a7:3d:3b:00:0d:b9:53:e8:35
05:00:01 dhcpcd[704] : dhcpcd-10.1.0 starting
00:01:47 dhcpcd[2545] : received SIGALRM, releasing
00:01:47 dhcpcd[2545] : received SIGALRM, releasing
00:01:47 dhcpcd[2545] : ps_root_recvmsg: Broken pipe
00:01:47 dhcpcd[2545] : ps_root_writeerror: result=0, data=(nil), len=0: Broken pipe
00:01:47 dhcpcd[2545] : script_runreason: No such process
00:01:40 dhcpcd[10822] : waiting for pid 2544 to exit
00:01:40 dhcpcd[10822] : sending signal ALRM to pid 2544
00:01:39 dhcpcd[10748] : pid 2544 failed to exit
00:01:29 dhcpcd[10748] : waiting for pid 2544 to exit
00:01:29 dhcpcd[10748] : sending signal ALRM to pid 2544
00:01:28 dhcpcd[10423] : pid 2544 failed to exit
00:01:18 dhcpcd[10423] : waiting for pid 2544 to exit
00:01:18 dhcpcd[10423] : sending signal ALRM to pid 2544
00:01:17 dhcpcd[10245] : pid 2544 failed to exit
00:01:07 dhcpcd[10245] : waiting for pid 2544 to exit
00:01:07 dhcpcd[10245] : sending signal ALRM to pid 2544
00:01:06 dhcpcd[9870] : pid 2544 failed to exit
00:00:56 dhcpcd[9870] : waiting for pid 2544 to exit
00:00:56 dhcpcd[9870] : sending signal ALRM to pid 2544
00:00:55 dhcpcd[9439] : pid 2544 failed to exit
00:00:52 dhcpcd[2545] : red0: deleting default route via 192.168.0.1
00:00:52 dhcpcd[2545] : red0: deleting route to 192.168.0.0/24
00:00:52 dhcpcd[2545] : red0: releasing lease of 192.168.0.14
00:00:52 dhcpcd[2545] : received SIGALRM, releasing
00:00:52 dhcpcd[2545] : red0: removing interface
00:00:52 dhcpcd[2545] : received SIGALRM, releasing
00:00:45 dhcpcd[9439] : waiting for pid 2544 to exit
00:00:45 dhcpcd[9439] : sending signal ALRM to pid 2544
00:00:44 dhcpcd[9366] : pid 2544 failed to exit
00:00:34 dhcpcd[9366] : waiting for pid 2544 to exit
00:00:34 dhcpcd[9366] : sending signal ALRM to pid 2544
00:00:33 dhcpcd[9141] : pid 2544 failed to exit
00:00:23 dhcpcd[9141] : waiting for pid 2544 to exit
00:00:23 dhcpcd[9141] : sending signal ALRM to pid 2544
00:00:22 dhcpcd[8985] : pid 2544 failed to exit
00:00:12 dhcpcd[8985] : waiting for pid 2544 to exit
00:00:12 dhcpcd[8985] : sending signal ALRM to pid 2544
00:00:11 dhcpcd[8604] : pid 2544 failed to exit
00:00:01 dhcpcd[8604] : waiting for pid 2544 to exit
00:00:01 dhcpcd[8604] : sending signal ALRM to pid 2544
I am not sure. The lease for the IP is an hour and just under an hour is the frequency of the failed to renew. However it then rebinds and gets given the same IP.
Are you hearing the disconnect/reconnect beep every hour?
I notice that it is a private range IP. Do you get that private IP directly from the ISP or do you have an additional router from the ISP between your IPFire and the ISP?
If it is a router from the ISP, I would expect that the 192.168.0.14 IP would just be renewed.
When I used to have a router from my ISP in front of my IPFire, it always stayed connected and I never got the failed to renew DHCP message.
1 Like
What is the condition of the hardware that IPFire is on? Could the reboots be related to failing motherboard, disk drive, power supply, etc?
1 Like
There is a router before IPfire. I have requested the Username and pw for a look-see. Time is updated hourly; and IP, BL were 2 months dated. Leave it for now. Best regards,
Reading the thread once more, there arouse a question.
Are we talking about system restarts or connection restarts?
As far I can see there is no display in the WUI of the system uptime, System > Home shows connection uptime only.
I made a /etc/init.d/network restart red some minutes ago.
WUI shows Connected - (9m 19s)
uptime from the CLI gives 16:58:00 up 13 days, 39 min …
does the Serial report sheds light on the issue:
[root@ipfire ~]# /etc/init.d/network start
Bringing up the green0 interface…
Adding IPv4 address 192.168.2.2 to the green0 interface…
Error: ipv4: Address already assigned. [ FAIL ]
Bringing up the blue0 interface…
Adding IPv4 address 192.168.5.2 to the blue0 interface…
Error: ipv4: Address already assigned. [ FAIL ]
Bringing up the red0 interface…
Starting dhcpcd on the red0 interface…dhcpcd already running! [ WARN ]
Adding static routes… [ OK ]
Adding static routes… [ OK ]
Mounting network file systems… [ OK ]
[root@ipfire ~]# /var/log/messages
-bash: /var/log/messages: Permission denied
[root@ipfire ~]# less /var/log/messages
Jan 30 08:01:03 ipfire syslogd 1.5.1: restart (remote reception).
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org. AAAA IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org.localdomain. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org.localdomain. AAAA IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org. AAAA IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org.localdomain. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org./var/log/messages
immediately after asking Serial for the above, the iffier mini appliance squeaked and reconnected. Took a picture now but before it said 1 minute.

And does the time delta for the squeak match with the timestamp for one of the messages in the RED logs for red0: failed to renew DHCP, rebinding?
1 Like
deaf dumb and blind. What is the Date and time? Turned Serial on again and it immediately printed:
…skipping…
Jan 30 08:01:03 ipfire syslogd 1.5.1: restart (remote reception).
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Can’t verify the Delta presently. Will wait for it to squeak again. What is the meaning of the Jan 30 08:01.03 date/time when today is Feb 03?
The meaning of the false date/time is documented in the second error message you posted.
Your IPFire device isn’t able to update date/time info because of problems with DNS resolution.
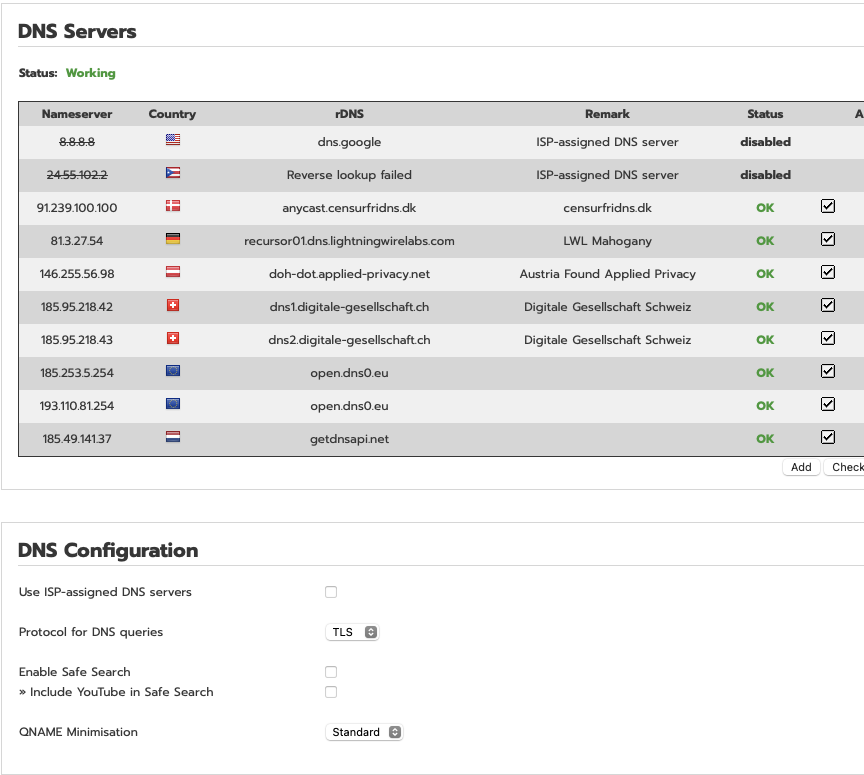
I use a simple DNS server ( 8.8.8.8, dns.google ) without TLS. This server isn’t really commended for production, but it delivers the DNS info for the startup.
Don’t know whether IPFire reboots if not getting NTP info after some time.
rebooted ipfire.
DNS ought not to be 8.8.8.8
and date is still jan 30.
what is the REMEDY?
root
Password:
No mail.
[root@ipfire ~]# /etc/init.d/network restart red
Umounting network file systems… [ OK ]
Stopping dhcpcd on the red0 interface…failed to stop dhcpcd! [ WARN ]
Bringing down the red0 interface… [ OK ]
Bringing up the red0 interface…
Starting dhcpcd on the red0 interface… [ OK ]
DHCP Assigned Settings for red0:
IP Address: 192.168.0.14
Hostname: ipfire
Subnet Mask: 255.255.255.0
Default Gateway: 192.168.0.1
DNS Server: 8.8.8.8 24.55.102.2
Adding static routes… [ OK ]
Adding static routes… [ OK ]
Mounting network file systems… [ OK ]
[root@ipfire ~]# less /var/log/messages
Jan 30 08:01:03 ipfire syslogd 1.5.1: restart (remote reception).
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org. AAAA IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org.localdomain. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <0.ipfire.pool.ntp.org.localdomain. AAAA IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org. AAAA IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org.localdomain. A IN>: all the configured stub or forward servers failed, at zone . upstream server timeout
Jan 30 08:01:04 ipfire unbound: [4273:0] error: SERVFAIL <1.ipfire.pool.ntp.org./var/log/messages
looks like an attack! I received 95 hits at exactly the same second
:15:28:10 suricata: error parsing signature “drop tcp $EXTERNAL_NET any → $HOME_NET $HTTP_PORTS (msg:“MALWARE-BACKDOOR Jsp.Webshell.Noop upload attempt”; flow:to_server,established; content:“java.util.*”; content:“java.io.FileOutputStream”; distance:0; content:“request.getParameter(|22|name|22|)”; within:200; fast_pattern; content:“confluence”; nocase; content:“request.getParameter(|22|contentString|22|)”; isdataat:!300,relative; metadata:policy balanced-ips drop, policy max-detect-ips drop, policy security-ips drop, ruleset community, service http; reference:cve,2022-26134; reference:url,community.atlassian.com/t5/Confluence-discussions/CVE-2022-26134-Critical-severity-unauthenticated-remote-code/td-p/20456533; classtype:trojan-activity; sid:59933; rev:2;)” from file /var/lib/suricata/community-community.rules at line 4021
As Bernhard has suggested your DNS is not working.
I note you are using TLS for DNS. Does your DNS providers use TLS?
If not it wont work.
As suggested use google to test. It wont be a huge issue.
login to console.
See if you can ping 8.8.8.8.
Can you resolve a dns name www.ipfire.org for example.
nslookup www.ipfire.org
Does it come back with an ip address.
secondly it sounds like you are using the upstream router to connect you to the internet and provide NATing for you.
So its unlikely you are being hacked as the NAT will make that more difficult.
Or:-
Do you have another device on your network, switch or device handing out DHCP ip addresses which is getting in before your internet device can get one. That would cause a clash where either device could answer to a refresh of address.
This would appear as an internet disconnect.
Worth checking out.
If you can see the internet ie ping 8.8.8.8 thats a good start.
It won’t prove if you have 2 dhcp servers on the red interface.
So you will need to think about that. Try connecting to various devices if you have then to see if there is a dhcp server on them.
HTH
Joe.
1 Like
The reason for failing dns may be the incorrect time. (org domain is DNSSec signed and the check fail.)
But even without dns IPFire should set the time via an hardcoded timeserver IP that is used if dns fails.
Have you blocked outgoing NTP?
1 Like