You are right. There are some postings about enhancements of Update Accelerator ( most authored by me ).
Short answer about current development. There is nothing in progress at the moment.
I had an idea about enhancements some years ago. But there wasn’t really much echo from the community. Because I’m running a very small system (ALIX) still, I do not use UPX at the moment. Therefore there isn’t a personal need to develop the enhancements.
If there is interest, we can discuss the main topics:
The managed update sources ( called vendors ) are identified by matching the URL supplied by squid in a long if-then-else statement. Modifications or additions can only be done by source code modifications. This isn’t really maintainable ( from a developers sight ).
The sequence of the conditions determines the runtime of the function. Vendors searched first are handled quick, vendors at the end of the statement need more runtime. This behaviour can be tolerated, if the sequence of matches maps to the distribution of requests. But this cannot be established. Every network managed by IPFire has its own request frequency.
Therefore I propose two modifications: The request URLs defining a specific vendor are given as regular expressions. Combining them to one expression per vendor allows a single match to identify the vendor. The description of a vendor (URLs, attributes, … ) can be placed into a description file. All those files are ‘compiled’ like the languages files. The search loops through this description data structure. To speed up the search adapted to the local requirements, the search order maps to a somewhat frequency table. The keys(vendor names) are sorted according to the usage history. So the most frequently requested vendors are matched first.
At the moment the data ( files, creation dates, size, … ) are held in a directory structure. A sort of data base can probably speed up the access to this data. My first attempt used the DBM::Deep perl module.
There is the ( theoretical ) possiblity to limit the download to the repository. The current implementation uses the limitation option of wget. But this is useless, if multiple instances of the download process are running. A dedicated download demon ( vendor repo → local repo ) could handle this. Is it possible to initiate multiple downloads adhering the download limit?
To restart the development it would be interesting to know the number of systems which use UPX.
Because of the ‘nature’ of squid only HTTP URLs can handle safely. Which ‘vendors’ with which URLs are used/necessary? ( I didn’t look at the status quo, yet )
Is it enough to define the structure/syntax of the definition files and the compile/restart processs?
This isn’t complete, just a discussion base out of my memory.
I too ask myself, how many are using UPX, simply because I doubt that most of the OS or applications in general, out there are downloading updates using https and according to your reply UPX is not of much help here.
Further more and to my knowledge, Windows 10 is using a special update manager which does not allow UPX to intervene.
Nevertheless, I’ve reactivated UPX yesterday but did not encounter any files in its statistics so far.
I believe the Update Accelerator is a dying thing. That is because of two reasons:
HTTP is dying, especially for this kind of file transfers. I would highly doubt that this feature is effective right now. It does things, but most of the updates are probably bypassing it already.
Bandwidth is usually not a big issue any more. Offices have good bandwidth and even at home, having a slow connection is probably more of an exception now than common.
So I would say that the team can probably invest their time better into features that are more beneficial for all users instead of doing a rewrite of the Update Accelerator. Making a couple of changes to the existing version doesn’t hurt though.
Thanks for the answer.
This is my opinion also. Therefore I didn’t invest more time since then.
Nevertheless I thought, it could be interesting to supply my ideas for the rewrite. Just in case there are real use cases in several areas. Not everywhere one has real broadband internet access.
I think Update Accelerator can be interesting in a scenario like this:
WAN access isn’t really fast ( < 10MBits/s )
more than 10 local devices load the same updates from the same address. So the double download the first time ( one DL from the requestor, one DL by Update Accelerator to the repository ) doesn’t hurt.
the same updates use the same download address. This isn’t true now for each update; Microsoft for example uses more and more ‘personalized URLs’.
In all other cases ( biggest part? ) Update Accelerator isn’t really effective/efficient. So all efforts in an efficient implementation don’t pay.
If there are really installations, which use the module, it maybe worth to review the current code in terms of efficiency and correctness.
I enabled Update Accelerator more than a year ago and promptly forgot all about it. So I have no clue if it works. But I was very surprised to find 200+ files saved.
That is true, but my point was that this is rather normal than the exception.
So if it comes to how I would prioritise development time for various features, it wouldn’t be the top priority because not many people use it. Actually the proxy as a whole is a very dying thing.
we’re using UPX for seven months right now; during this time, it collected ~5.400 files (roundabout 135 GiB).
it delivered ~5 TiB to the network (~25 systems, most of them windows, but also debian & ubuntu virtual & physical appliances).
Before UPX monthly updates (especially MS) took much more than one hour over all although we have 1 GBit/s connectivity in the data centre.
This means Update Accelerator makes sense, even nowadays with fast internet connectivity. So it is worth to look through the code of the existing function.
A rewrite may be worthwhile, but till now I know about single usages only.
To add another comment (from a Linux perspective): most distros use HTTP (or FTP) for the package gets and rely on signing (with secure key exchange) for verification. This works well, and in my case (small setup - 8 computers) I get a 3 : 1 useage : read ratio.
Most of the public infrastructure is sponsored or provided for free by the community so anything we can do to lighten the load is a good idea.
At the risk of being contentious (ref: Audacity) it would be a good idea, for situations like this, if there were a trusted mechanism (? AddOn) for collecting usage and performance stats for IpFire AddOns.
Yes, IPFire does that too, but we have decided to enforce HTTPS on all our mirror servers for privacy reasons. Otherwise it would be possible for a MITM to figure out which updates have been downloaded and therefore know the patch level of a system. This is an information leak that we wanted to close.
We also avoided this by having a mirror infrastructure that is hosted by either us, universities and other (in our eyes) trustworthy parties. It is not possible that a single mirror is able to collect a list of all IP addresses of IPFire systems because that list would allow someone to target a large number of IPFire systems.
Therefore traffic is cheap for us (and IPFire is a small system so that updates don’t accumulate petabytes of traffic) and we decided to pay that price in favour of privacy.
Yes, this is a very good example. I feel for many companies behind Open Source projects, making money isn’t easy these days. People like free stuff. However, development, support, hosting - it all costs money. Some try things that I very much disagree with (for example Audacity and Elasticsearch) as they never work. So, if you can, support the software projects you like with a donation
First, Thanks for the detailed response.
As said above, it is worth to do a rethink of my former design.
At least a rewrite of the parsing should be done.
The answer to your question is no.
Update Accelerator must analyse the web requests for update sites. The part in IPFire which handles these packets is the web proxy ( Squid ). Therefore Update Accelerator is best realised as a filter process of this program.
It could be made independent of Squid, but this would mean to establish a second parallell proxy. This isn’t without complications.
Squid should be active always and thus Update Accelerator also. Web pages blocked by Squid shall not be reached ( at your definition ) and cannot supply updates.
So Update Accelerator handles all allowed update sites.
Actually, there is a continued need for UA as I use it and I know of others as well. In the African context, internet is not fast in general, is metered and expensive. So, UA makes sense in such locations. Way back in the IPCop days, it was UA that proved to be the “killer app” for us in Cameroon helping to overcome serious bandwidth limitations and high costs. Though things have improved here, UA still has value.
When I started using IPfire a few years ago, i thought it was a pretty tool… But then when the internet started pushing for SSL/TLS connections, I didn’t really see a future in it because in those cases, it’s not just a host/port redirect, it’s a cert too and that can be troublesome. Recently, I started using it, because I read how update repositories are mostly still HTTP. The problem I run into is when I’m using certain WebApp software, the WebProxy interferes and breaks my connection.
I would very much like to see further development on this project. UPX can address many issues
reduce external data transfer for consumption based billing
leverage higher LAN speeds for updates
reduce the requsts from a network for updates ( projects like ClamAV throttle you and some devices may never get signature updates. Oh how I would love caching signature updates)
and more…
Another project I was looking into was LANcache, but it seems quite overkill. Also Dedicated rsync and ClamAV mirrors are a bit overkill too. I’m not much for coding in Perl, but I would offer any assistance I can.

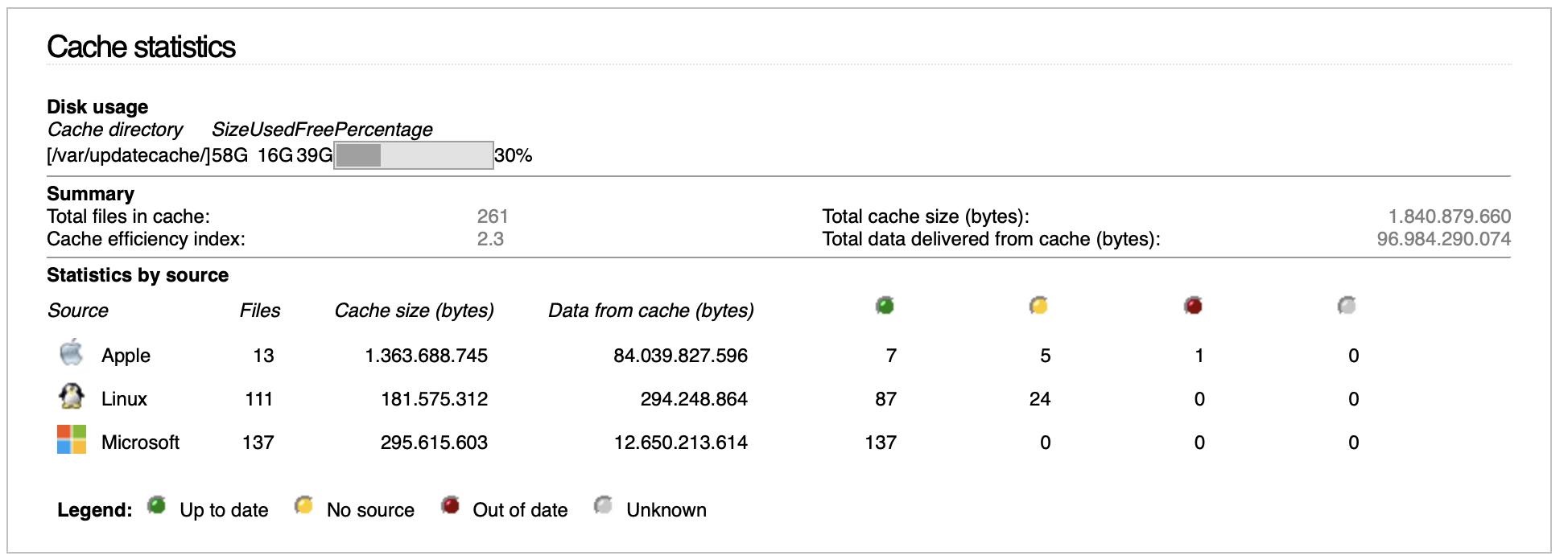



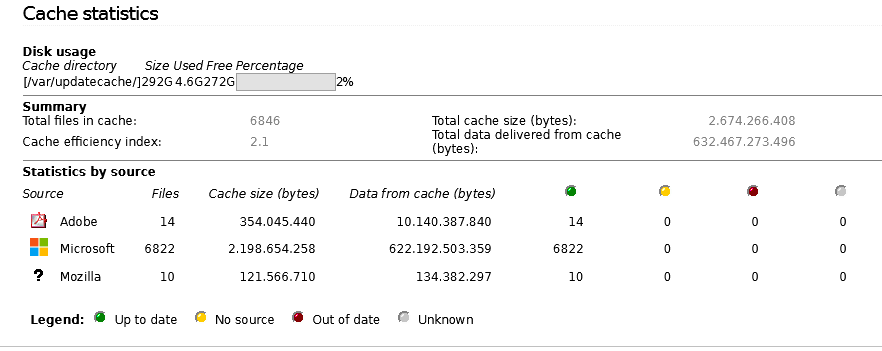

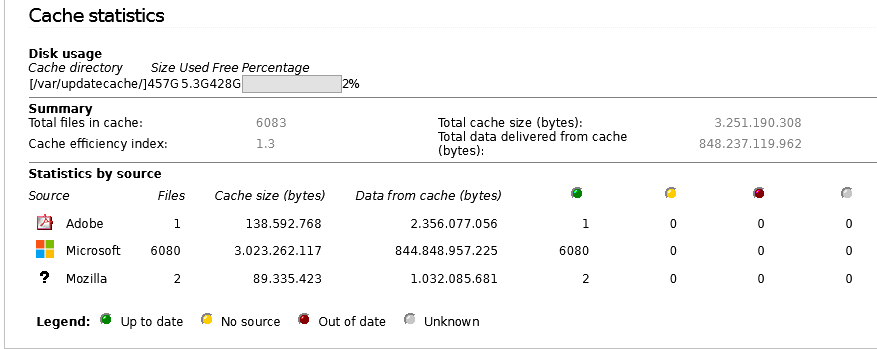
 (after some upgrade).
(after some upgrade).