I have a Red/Orange/Blue network running on an Intel N100 3.6GHz with four NICs and 8GB RAM and IPFire 229 update 185. It works quite well, with a low load average (usually 0.0) and lots of memory free. Traffic volume is pretty low, typically under 1mbps. Network is 1gbps and internet service is 1gpbs, with 1gbps down and 40mbps up.
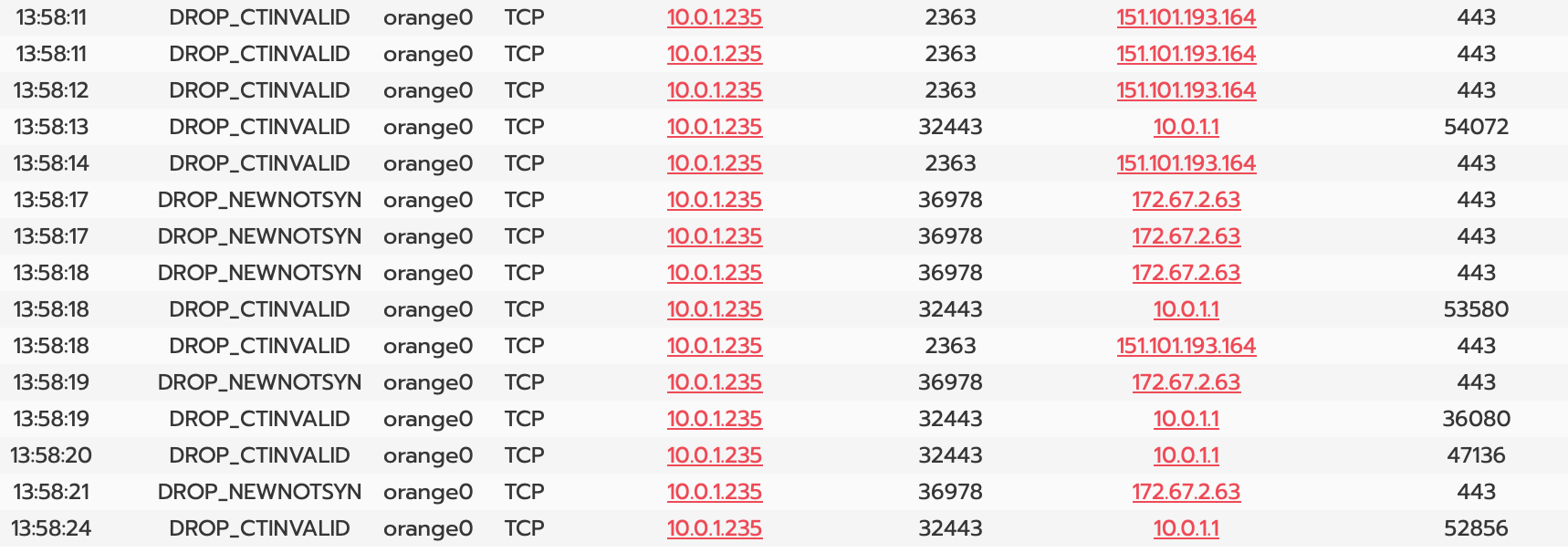
I’m noticing a lot of DROP_CTINVALID and DROP_CTNEWNOTSYN in the logs and I’m trying to understand why. Internally, they appear on both the orange and blue networks, whether communicating with internal hosts (like the firewall) or external ones.
This is a linux machine in the orange network, which receives inbound traffic on 32443 from haproxy running on the IPFire host. It also makes outbound traffic on port 443.
I’m a bit new to this, and so I looked into MTU issues, but some machines use Path MTU Discovery, and for internal network this wouldn’t apply since they all have an MTU of 1500 on their NICs. For those reasons I’m doubtful it’s an MTU problem.
But now I’m stumped. I didn’t expect to see these packets dropped, and I cannot understand why they’d be appearing on the LAN/WLAN side so often. Any ideas why netfilter is dropping these packets? I struggle to believe that there’s a problem with the TCP.
It’s worth noting that I’m using a stock /etc/sysctl.conf file. I’m digging into conntrack and the various TCP settings to see if there’s some known issue; so far nothing has turned up.
One slight possibility is some kind of issue with tcp_fastopen, but I’m doubtful.
Also, there’s no mention of conntrack in /var/log/messages, or anything else unusual that I can see.
Still digging. I found this article which says, in essence, “there’s a windows bug that causes this to happen sometimes,” except these hosts aren’t running Windows.
But, at least now I know the rule that’s dropping the NEWNOTSYN packets. I don’t think it should be enabled anywhere but red, however. Also it probably shouldn’t be triggered in the first place by normal stuff happening on my LAN: there shouldn’t be any new packets that aren’t syn packets.
WRT DROP_CTINVALID, here’s the iptables rule:
# iptables-save | grep CTINVALID
-A CTINVALID -m limit --limit 10/sec -j LOG --log-prefix "DROP_CTINVALID "
-A CTINVALID -m comment --comment DROP_CTINVALID -j DROP
Which appears to be limiting any/all TCP connections to 10 in a second. I’m doubtful that I’m hitting this limit internally, especially making outbound connections. Again, I think this should be disabled in the blue/orange/green zones, or at least increased. Can this be customized somehow?
For what it’s worth, I have a reproducible test case: two different browsers on my machine in blue run into a CT_NEWNOTSYN when communicating with a website hosted in orange, both on exactly the same request. I cannot access the device as a result, unless I port-forward in on an SSH connection, taking Conntrack out of the equation (the port-forwarded connection works perfectly).
NEWNOTSYN is generated if a tcp packet is recieved with no matching connection is the tracking table.
But if the reciever try to stop a connection with RST and the sender still sends fast or has not got this RST it will generate this DROP_NEWNOTSYN state because IPFire has already closed the connection. (It make also no sense to forward such packet because the reciever will also drop it.)
Normal you can ignore this and disable the logging in the firewall settings.
The problem here is that a connection that worked before I started using IPFire (really conntrack) now consistently doesn’t. I’m not sure where to take the issue from here: it seems as though either a TCP (or below) bug in Linux or MacOS that nobody else has found, or it’s a bug in conntrack that nobody else has found. Both seem equally unlikely.
The network topology is this:
MacBook Pro M1 talking WiFi to an eero.
Eero connected to blue NIC (Intel I-226V; igc driver, firmware 2013:8877)
IPFire 229 update 185 running on Intel N100
Orange NIC (another Intel I-226V)
Dumb unmanaged GigE switch
WD MyCloud PR4100 NAS
When I connect to the admin service on the mycloud, the HTTP connection works, until the response to the auth request never makes it back, being consistently shut by conntrack. I probably should grab a packet capture, but honestly I’m at a loss as to how I should proceed. This feels like software to me but I’m admittedly unfamiliar with the intricacies of modern TCP networking.
I don’t know why conntrack thinks the connection has closed; or why it thinks there’s a new packet. The problem first appears at 15:48:35.774527, and the connection is certainly open at the time.