Hi all, @cwensink i would check your OpenVPN logs not only by grepping for errors, may you can find there more informations. Nevertheless, there seems to be something really wrong with your OpenVPN configuration possibly you can also find this messages in the OpenVPN logs " TLS Error: TLS key negotiation failed to occur within 60 seconds", since this message appears very frequent, OpenVPN have decided to create an own page/checklist for this problem → https://openvpn.net/faq/tls-error-tls-key-negotiation-failed-to-occur-within-60-seconds-check-your-network-connectivity/ may you know it and or checked it ?
Another thing, it might be great if you can set the code tags if you post logs (easier to read).
Some ideas to one problem. May it might be also helpful if you sort the different problems (OOM, OpenVPN, Unbound, Smart status) a little more for your investigation but also for the community may some help comes faster ?
Not sure if it helps.
I have had no problem with core 169
Core update did add 2factor authentication to OPENvpn.
A feature I’m not using.
Not a tor addon user either as a side note.
How long has this appliance been in service and were any updates or changes made, no matter how minor, before the first crash instance?
What version and core update are you running?
The most worrying thing I’ve seen in this entire post are the drive IO errors. If the drive is failing, it will cause all sorts of random errors. Same can be said for memory though. I get SMART says the drive is healthy, but it’s not entirely reliable. Could be a physical issue as well like a loose power or data cable, maybe a failing port.
Not sure how long you can take this appliance out of service, but if no software changes were made, I would install a new drive, restore the latest backup file and run memtest.
Tuesday night I re-built a new IPFire machine, and the next two days have been quiet, errors for openvpn ended on 9/20 per the messages log. It’s entirely possible that all of this had nothing to do with IPFire and was related to hardware failure or possibly a security breach on the router, but the router is offline now.
Any suggestions on what utilities to run to test the hardware of the device? The machine is a Quad Core Atom processor 8, GB ram, 120 GB ssd Micro ITX Supermicro box 2.7.Ghz, and I am ok with any testing app in an offline environment.
This unit has been in service for about 5 years, and has had a number of changes in the configuration along the way. It first started having these major problems when running 169, and for troubleshooting I tried updating to 170, but that did not fix the issue. On this appliance there’s a power plug with an external power supply that’s similar to a laptop except the plug screws in on the end (like a water hose).
With the new machine in place and working I suppose the issue is resolved.
The issue appears to be an acute one. Working fine one day and then became crashy. I’m going with a hardware error again printing out the IO issues logged. You could still troubleshoot the old machine with the steps provided previously since it is now offline.
I will say that upgrading a machine experiencing issues is a bad idea. Updating the software could introduce a new bug compounding existing problems with new ones. Better to resolve any issues then upgrading.
Update to this issue. I now have had 3 different IPFire appliances gone down on me in the last 4 weeks. One is a custom build machine with a Xeon E3 CPU, 4 GB of ram and a WD Black 500 GB sata disk in it, which functioned just fine up until I took it offline for a hardware upgrade. I’ve since tried two different Supermicro Mini ITX Systems, Model 101S-6 P/N SYS-E200-9B, both have 8 GB of ram, and 120 GB SSD’s in them. Both of those units have experienced issues going down and randomly rebooting, with no clear cause. I had one reboot on my on Friday, and 30 minutes ago the system restarted again. Thankfully the system came back online so fast that nobody hardly noticed the downtime. I confirmed by connecting in via bash, and I see the uptime is just 1 minute.
I’m starting to feel like I am cursed. I’m searching /var/log/messages for any indication about what is happening but I am coming up with nothing.
Please read through the above posts by others. yes again.
Keep in mind you are our eyes in this situation.
There are suggestions above and little response from you (like post #21)
Are you using CU 170 on all three IPFire devices?
Pick one device you want to fix. Look for the time of failure and make note of it (for us and for you!)
Look through the logs starting at that time (time of issue) and go backwards about 10 minutes. If you don’t see anything notable, post the message log for entire 10 min time frame. (make sure we know what time it failed).
Same for the OpenVPN log.
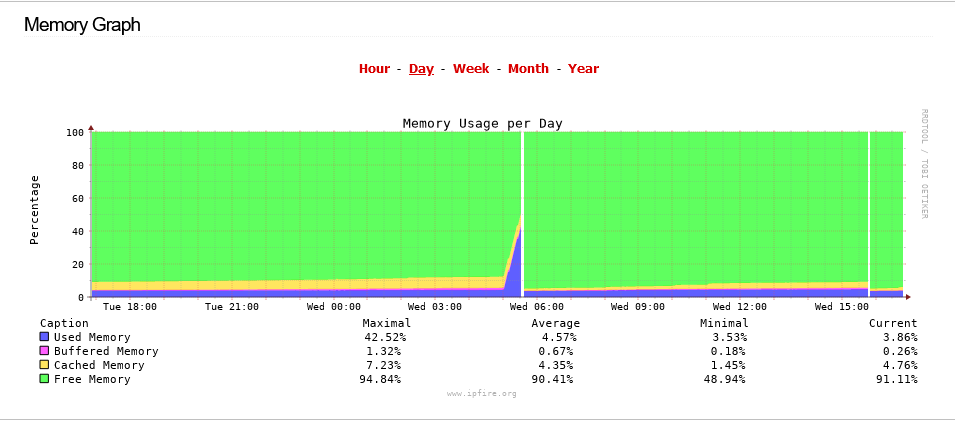
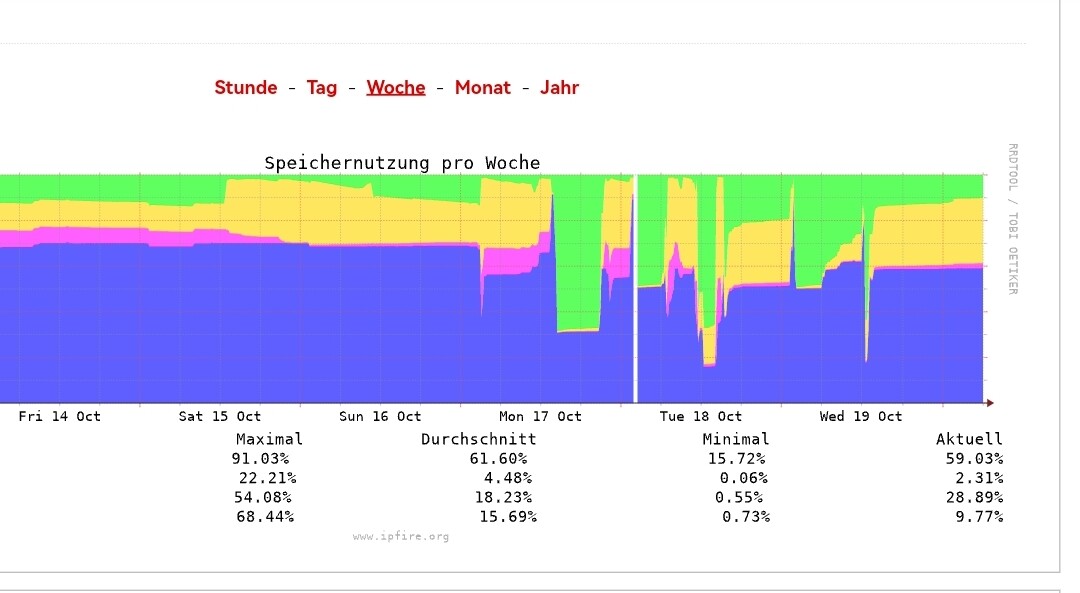
Look through the graphs (like Memory). Look at the same time. Did it spike again?
Jon, As I am writing this, the device has been online for 24 hours without issue, the device went down at 2:00 PM yesterday (10/17/22). At that time it had a sudden reboot. As I am writing this I see the CPU Spiking on 1 core at nearly 100%,
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.15.59-ipfire] (IPFire 2.27)
Copyright (C) 2002-22 Bruce Allen Christian Franke www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: KingDian M280 120GB
Serial Number: A4720783073000208341
LU WWN Device Id: 0 000000 000000000
Firmware Version: SBFM61.2
User Capacity: 120 034 123 776 bytes [120 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: Solid State Device
Form Factor: mSATA
TRIM Command: Available
Device is: Not in smartctl database 7.3/5319
ATA Version is: ACS-4 (minor revision not indicated)
SATA Version is: SATA 3.2 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue Oct 18 13:51:58 2022 CDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0
9 Power_On_Hours 0x0012 100 100 000 Old_age Always - 34376
12 Power_Cycle_Count 0x0012 100 100 000 Old_age Always - 374
168 Unknown_Attribute 0x0012 100 100 000 Old_age Always - 0
170 Unknown_Attribute 0x0003 095 095 000 Pre-fail Always - 52
173 Unknown_Attribute 0x0012 100 100 000 Old_age Always - 5636205
192 Power-Off_Retract_Count 0x0012 100 100 000 Old_age Always - 321
194 Temperature_Celsius 0x0023 067 067 000 Pre-fail Always - 33 (Min/Max 33/33)
218 Unknown_Attribute 0x000b 100 100 050 Pre-fail Always - 0
231 Unknown_SSD_Attribute 0x0013 100 100 000 Pre-fail Always - 97
241 Total_LBAs_Written 0x0012 100 100 000 Old_age Always - 10979
I swapped out the whole system, not just a drive, because I didn’t know if it was specifically a drive issue.
I have the old system on my desk here and I ran some tests on it. Both the unit in production and the unit on my desk have Identical hardware: Model 101S-6 Supermicro SYS-E200-9B. 4 Core Intel Pentium N3700 1.6 Ghz, 8GB ram, 120 GB m.2 sata ssd, 4x Intel Ethernet Controller i210 Gigabit Netework connection (rev03).
So the system did it yesterday and it did it again today where the system did some kind of a reboot, but honestly today it happened so fast that I didn’t even notice. The same thing happened yesterday, but I don’t know what is causing this situation. Attached is the bootlog. bootlog.gz (14.3 KB)
You can see the tiny white line between 3:30 and 4:00 PM today. The uptime on IPFire is 1 hour 3 minutes, as of 4:51 PM today so 3:48 is when the system went down / restarted for some unknown reason. This time not because of a memory load, the graph doesn’t show it, but something is still causing our system to go down now daily. Here’s the /var/log/messages for the 3:00 hour with security related info removed. 10-19-22-1500.txt.gz (159.1 KB)
The 05:30 crash is not in the message log. That might be the important one since memory usage starts climbing near 05:00.
I can find the one that happened at 15:46:43 (up at 15:48:05):
Oct 19 15:46:43 ipfire kernel: DROP_INPUT IN=red0 OUT= MAC=<red-mac-address>:84:bb:69:d2:b8:b0:08:00 SRC=47.35.152.95 DST=<External-IP> LEN=80 TOS=0x00 PREC=0x00 TTL=111 ID=57233 PROTO=UDP SPT=55342 DPT=64645 LEN=60 MARK=0x80000000
Oct 19 15:48:05 ipfire syslogd 1.5.1: restart (remote reception).
Oct 19 15:48:05 ipfire kernel: usb 1-5.2.2.1: New USB device found, idVendor=0557, idProduct=2419, bcdDevice= 1.00
I don’t see anything interesting in the message log. To me it acts like it is a power issue (lost power for whatever odd reason) or a maybe hardware problem. Maybe someone else can look and add there comments.
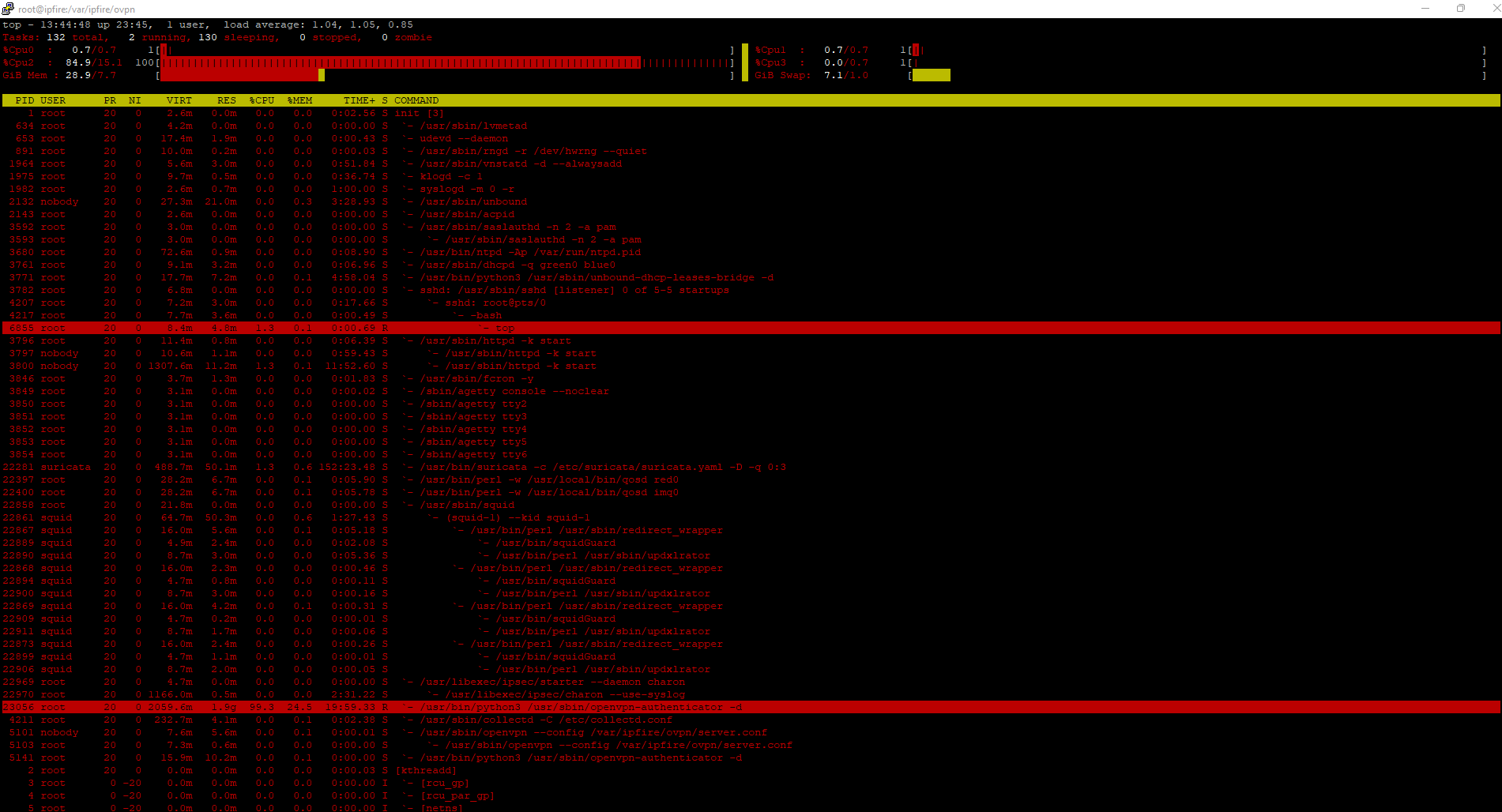
I have the same problem, this process (openvpn-authent) fills memory until full. This process occurs periodically every night or after a new certificate is created.
Other processes are then terminated.
I have now deleted the certificates and deactivated OpenVPN, since then the problem has not occurred again.