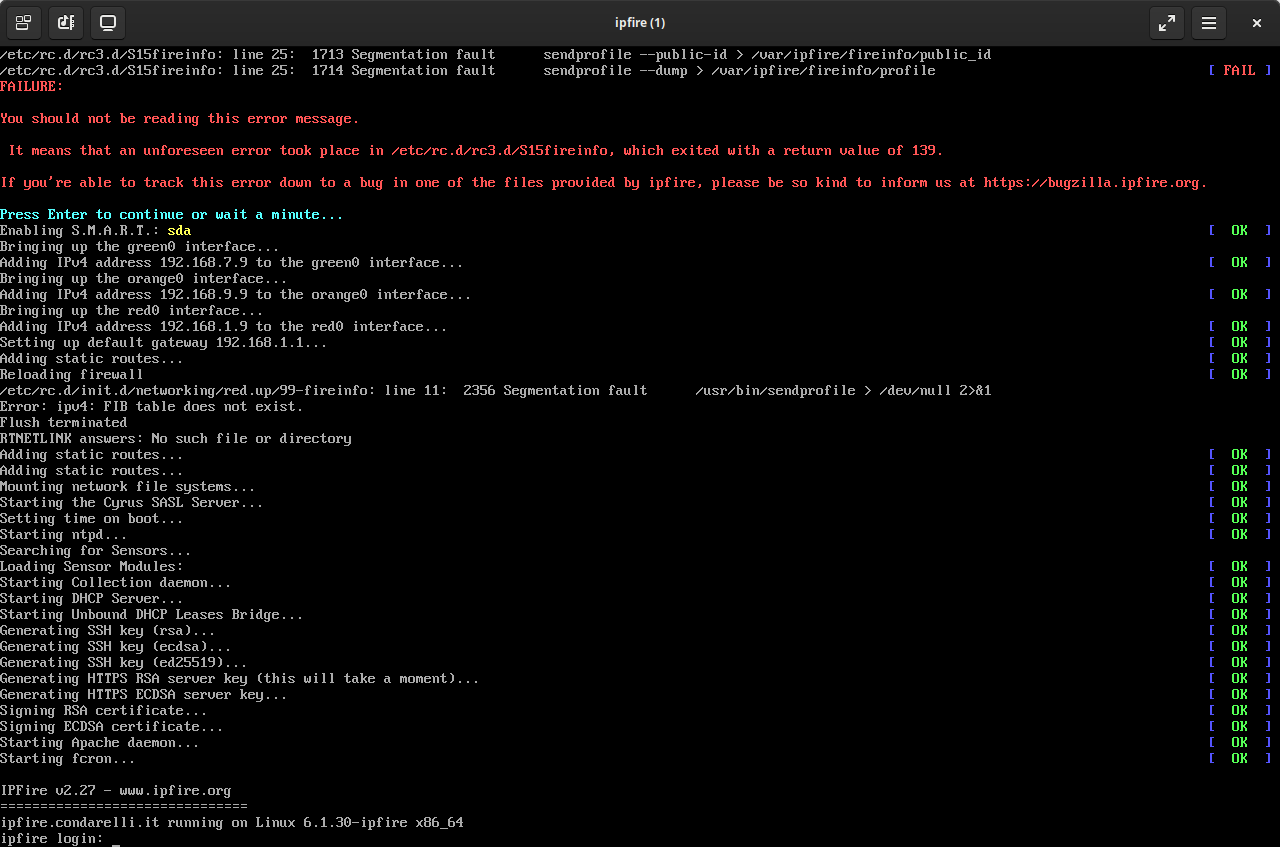
There must be some bug in relation to the qemu hypervisor and your hardware causing a problem.
The last change to the fireinfo code was in July 2021 to deal with the change of python from v2 to v3.
The c code involved is:-
/*
* Fireinfo
* Copyright (C) 2010, 2011 IPFire Team (www.ipfire.org)
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
#include <Python.h>
#include <errno.h>
#include <fcntl.h>
#include <linux/hdreg.h>
#include <stdbool.h>
#include <string.h>
#include <sys/ioctl.h>
/* hypervisor vendors */
enum hypervisors {
HYPER_NONE = 0,
HYPER_XEN,
HYPER_KVM,
HYPER_MSHV,
HYPER_VMWARE,
HYPER_OTHER,
HYPER_LAST /* for loop - must be last*/
};
const char *hypervisor_ids[] = {
[HYPER_NONE] = NULL,
[HYPER_XEN] = "XenVMMXenVMM",
[HYPER_KVM] = "KVMKVMKVM",
/* http://msdn.microsoft.com/en-us/library/ff542428.aspx */
[HYPER_MSHV] = "Microsoft Hv",
/* http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1009458 */
[HYPER_VMWARE] = "VMwareVMware",
[HYPER_OTHER] = NULL
};
const char *hypervisor_vendors[] = {
[HYPER_NONE] = NULL,
[HYPER_XEN] = "Xen",
[HYPER_KVM] = "KVM",
[HYPER_MSHV] = "Microsoft",
[HYPER_VMWARE] = "VMWare",
[HYPER_OTHER] = "other"
};
#define NEWLINE "\n\r"
static void truncate_nl(char *s) {
assert(s);
s[strcspn(s, NEWLINE)] = '\0';
}
static int read_one_line_file(const char *filename, char **line) {
char t[2048];
if (!filename || !line)
return -EINVAL;
FILE* f = fopen(filename, "re");
if (!f)
return -errno;
if (!fgets(t, sizeof(t), f)) {
if (ferror(f))
return errno ? -errno : -EIO;
t[0] = 0;
}
char *c = strdup(t);
if (!c)
return -ENOMEM;
truncate_nl(c);
*line = c;
return 0;
}
/*
* This CPUID leaf returns the information about the hypervisor.
* EAX : maximum input value for CPUID supported by the hypervisor.
* EBX, ECX, EDX : Hypervisor vendor ID signature. E.g. VMwareVMware.
*/
#define HYPERVISOR_INFO_LEAF 0x40000000
int detect_hypervisor(int *hypervisor) {
#if defined(__x86_64__) || defined(__i386__)
/* Try high-level hypervisor sysfs file first: */
char *hvtype = NULL;
int r = read_one_line_file("/sys/hypervisor/type", &hvtype);
if (r >= 0) {
if (strcmp(hvtype, "xen") == 0) {
*hypervisor = HYPER_XEN;
return 1;
}
} else if (r != -ENOENT)
return r;
/* http://lwn.net/Articles/301888/ */
#if defined(__amd64__)
#define REG_a "rax"
#define REG_b "rbx"
#elif defined(__i386__)
#define REG_a "eax"
#define REG_b "ebx"
#endif
uint32_t eax = 1;
uint32_t ecx;
union {
uint32_t sig32[3];
char text[13];
} sig = {};
__asm__ __volatile__ (
/* ebx/rbx is being used for PIC! */
" push %%"REG_b" \n\t"
" cpuid \n\t"
" pop %%"REG_b" \n\t"
: "=a" (eax), "=c" (ecx)
: "0" (eax)
);
bool has_hypervisor = !!(ecx & 0x80000000U);
if (has_hypervisor) {
/* There is a hypervisor, see what it is... */
eax = 0x40000000U;
__asm__ __volatile__ (
" push %%"REG_b" \n\t"
" cpuid \n\t"
" mov %%ebx, %1 \n\t"
" pop %%"REG_b" \n\t"
: "=a" (eax), "=r" (sig.sig32[0]), "=c" (sig.sig32[1]), "=d" (sig.sig32[2])
: "0" (eax)
);
sig.text[12] = '\0';
*hypervisor = HYPER_OTHER;
if (*sig.text) {
for (int id = HYPER_NONE + 1; id < HYPER_LAST; id++) {
if (strcmp(hypervisor_ids[id], sig.text) == 0) {
*hypervisor = id;
break;
}
}
}
return 1;
}
#endif
return 0;
}
static PyObject *
do_detect_hypervisor() {
/*
Get hypervisor from the cpuid command.
*/
int hypervisor = HYPER_NONE;
int r = detect_hypervisor(&hypervisor);
if (r >= 1) {
const char* hypervisor_vendor = hypervisor_vendors[hypervisor];
if (!hypervisor_vendor)
Py_RETURN_NONE;
return PyUnicode_FromString(hypervisor_vendor);
}
Py_RETURN_NONE;
}
static PyObject *
do_get_harddisk_serial(PyObject *o, PyObject *args) {
/*
Python wrapper around read_harddisk_serial.
*/
static struct hd_driveid hd;
const char *device = NULL;
char serial[22];
if (!PyArg_ParseTuple(args, "s", &device))
return NULL;
int fd = open(device, O_RDONLY | O_NONBLOCK);
if (fd < 0) {
PyErr_Format(PyExc_OSError, "Could not open block device: %s", device);
return NULL;
}
if (!ioctl(fd, HDIO_GET_IDENTITY, &hd)) {
snprintf(serial, sizeof(serial) - 1, "%s", (const char *)hd.serial_no);
if (*serial) {
close(fd);
return PyUnicode_FromString(serial);
}
}
close(fd);
Py_RETURN_NONE;
}
static PyMethodDef fireinfo_methods[] = {
{ "detect_hypervisor", (PyCFunction) do_detect_hypervisor, METH_NOARGS, NULL },
{ "get_harddisk_serial", (PyCFunction) do_get_harddisk_serial, METH_VARARGS, NULL },
{ NULL, NULL, 0, NULL }
};
static struct PyModuleDef fireinfo_module = {
.m_base = PyModuleDef_HEAD_INIT,
.m_name = "_fireinfo",
.m_size = -1,
.m_doc = "Python module for fireinfo",
.m_methods = fireinfo_methods,
};
PyMODINIT_FUNC PyInit__fireinfo(void) {
PyObject* m = PyModule_Create(&fireinfo_module);
if (!m)
return NULL;
return m;
}
I would suggest raising a bug on this.
https://wiki.ipfire.org/devel/bugzilla
https://bugzilla.ipfire.org/
Your IPFire People email address and password will act as your login credentials for the IPFire Bugzilla.