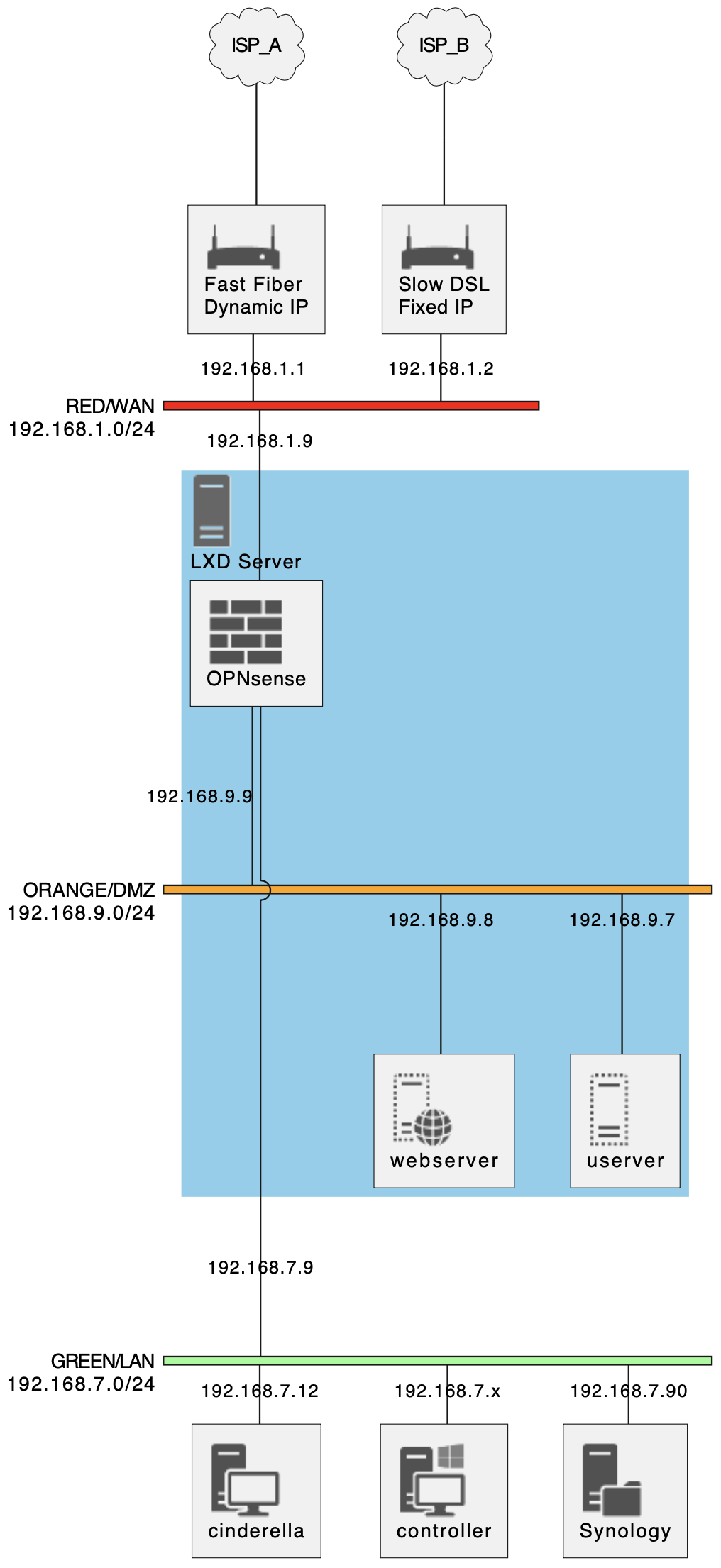
I have the following setup:
- RED + GREEN + ORANGE
- Orange has a couple of hosts (mainly used as web server)
- GREEN has some workstations(~10) and a NAS (doubling as GIT repository)
- RED has TWO, currently asymmetric) fiber modems:
- Fast (1000Mb/s) one with dynamic public IP (unreacheable from the Internet)
- Slow (200Mb/s) one with static public IP (connected to domain I own)
I am currently using “slow” for all my traffic, but I would like to “optimize” a bit.
In general I think I should set up things so that connections originating from GREEN
(and possibly also ORANGE) should go through Fast while connections originating
from the Internet (presumably on Slow, but this may change) should go back using
the “right route” (i.e.: wherever they came from).
Incoming connections can currently go to:
- a server on ORANGE (80 and 443 at least)
- NAS on green (accessing GIT through secured SSH connection on non-standard port).
- I am wondering about moving all reverse proxy/virtual-server handling to IPFire
(currently all http[s]:// stuff is sent to a single server on ORANGE and handled there).
I am a bit confused about how to setup this beast (and I’m unsure it even makes sense)
as I’m not a real networking expert, even tough I’m meddling with the stuff since a lot
of time.
Cross-check and advice would be very welcome.
Many Thanks in Advance