I have a curious behavior here on my system since the update to Core 180.
On my system I have QEMU installed and about 4 VMs running as well as a VM with CheckMK (monitoring).
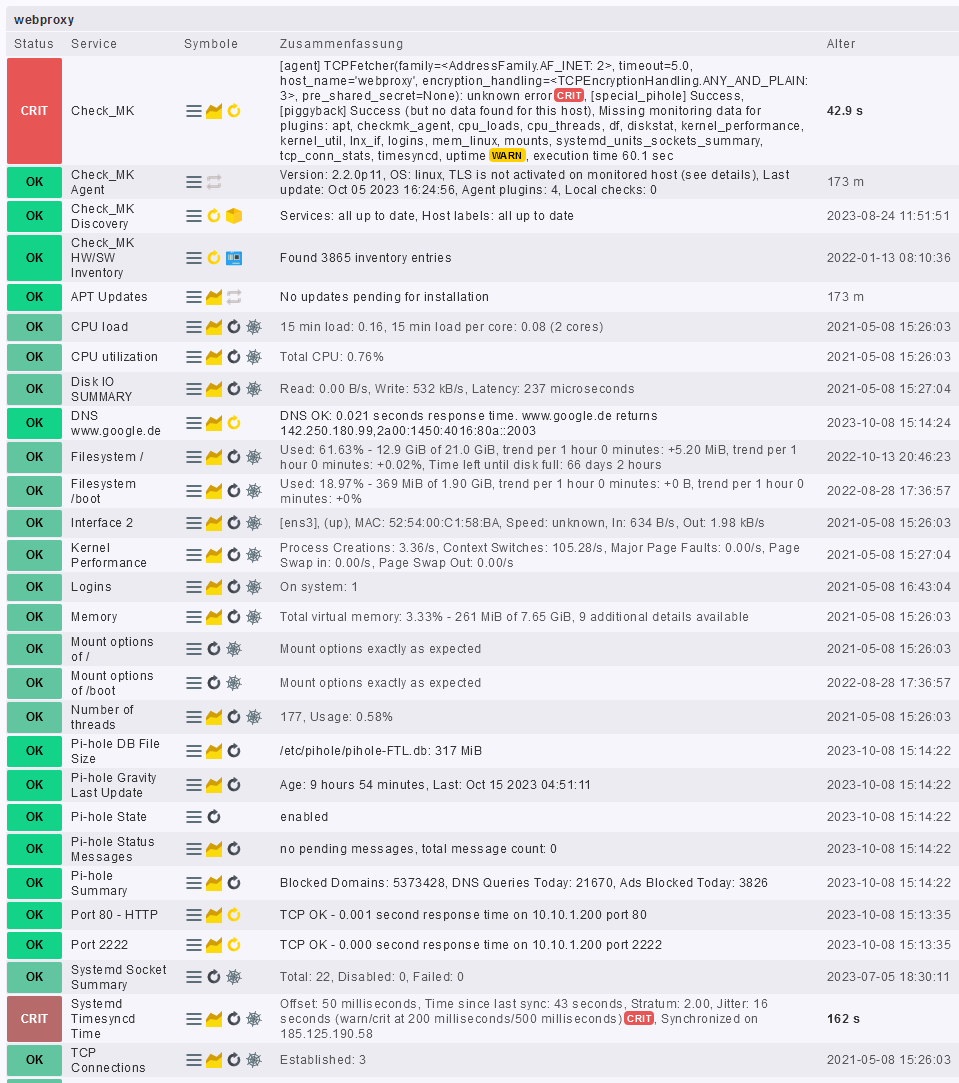
My CheckMK now repeatedly reports connection losses to the monitored systems or their agents.
I definitely have this only since the update and can’t explain it at all or make sense of it. The systems are always reachable via normal ping and sometimes have up to 15ms response time instead of the usual 1ms.
The services checks from CheckMK are also shown as OK after a while.
Here’s what I could briefly see as a message on CheckMK when it lost connection to the agent on the hosts.
.
.
The previous QEMU version was 8.10.0 and there was no problem or behavior.
. OLD
libvirt version: 8.10.0, qemu version: 8.0.3, kernel: 6.1.45-ipfire
. NEW
libvirt version: 8.10.0, qemu version: 8.1.1, kernel: 6.1.45-ipfire
.
How can I switch back to version 179 without an extremely time-consuming reconfigure of the whole system?
There seems to be a massive bug or something similar in the QEMU AddOn.
welcome back on board! I too have just massive problems with directly looped SATA drives, which have now broken out only since installing the update to Qemu 8.1.1.
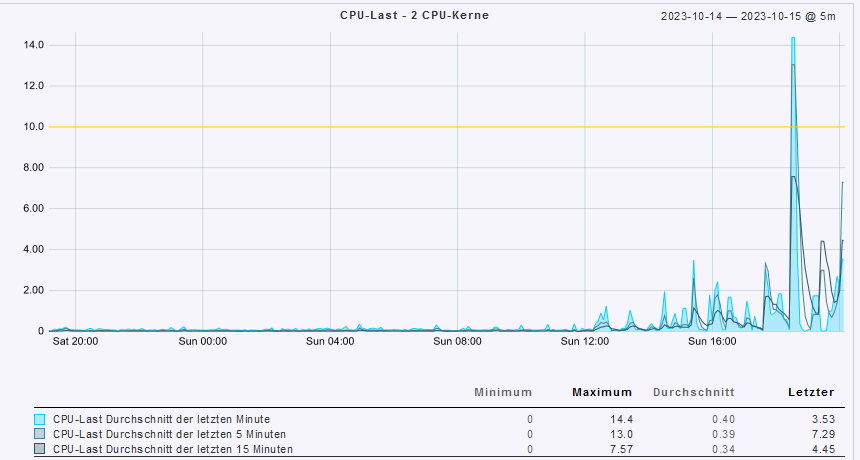
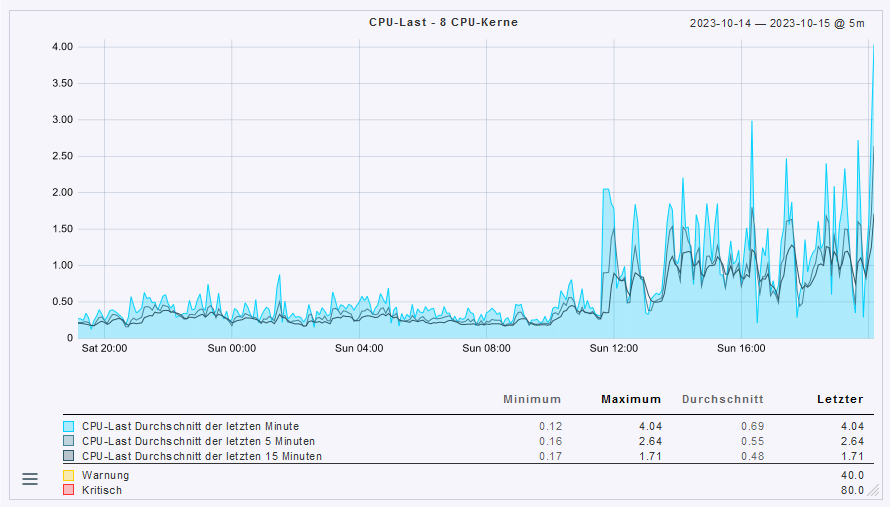
However, I can not see any higher load or similar at the time on all my running machines.
Is there any way to reinstall the old QEMU without reinstalling ipfire.
My systems at home have such a CPU load that my web proxy (pi-hole) is constantly unavailable and we can’t surf or work.
I am unfortunately able to create a patch here as I can’t even capture what triggers this CPU load after the update but it affects all VMs that I run via QEMU.
You need to be able to have a discussion with someone who is an expert in using qemu (which I am not) and who, from the symptoms you are describing, can suggest what to look for in logs or other files.
That is why I suggested reporting this issue into the qemu gitlab issues web page as it would then get reviewed by the qemu devs who should be expert enough to help.
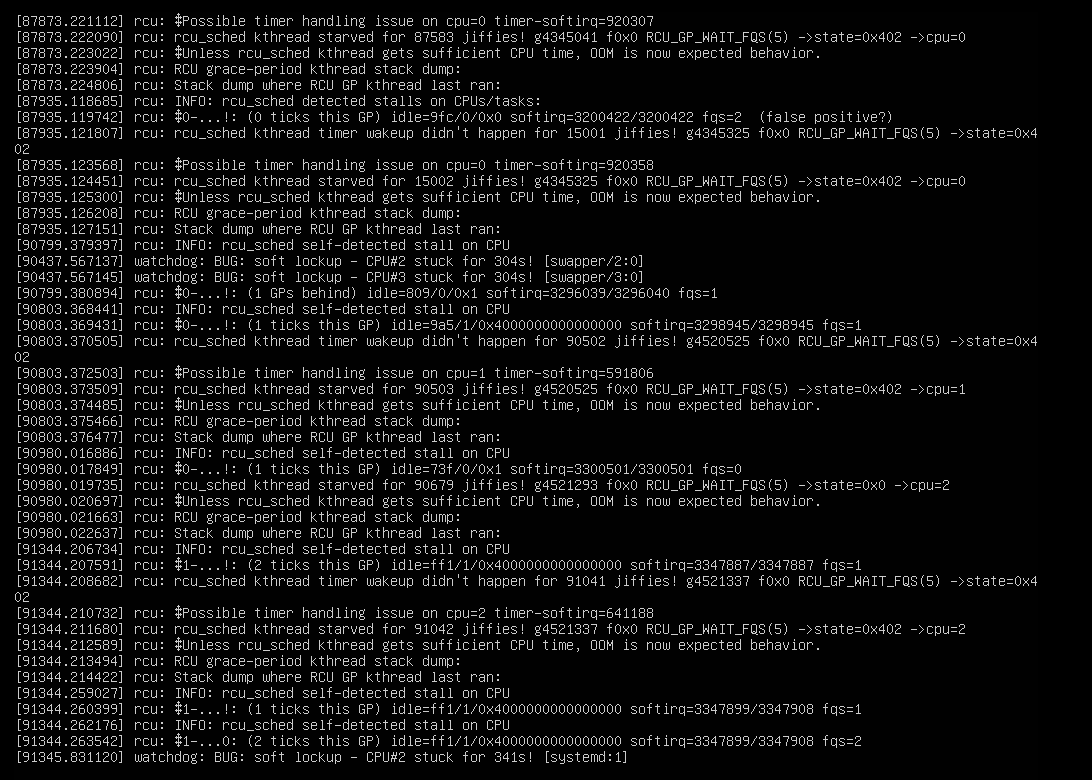
As I said I am not an expert but my interpretation of lines like
“unless rcu_sched kthread gets sufficient CPU time” and
"rcu_sched kthread starved for 90679 jiffies!
is that something else is hogging the cpu time and preventing qemu from getting sufficient or maybe any access to the cpu processing.
I would install the htop addon and have a look at what program is consuming the largest chunk of that cpu time.
It could also still be something from qemu. I found slightly similar rcu messages from an application called OPTEE. There they identified the problem to be coming from qemu when it was updated from 7.0.0 to 7.1.0 and was linked with commits in qemu interacting with changes in the kernel.
It is clearly not related to a kernel change here, as there wasn’t a kernel update in CU180 but could definitely still be qemu related.
It would be interesting to see what if it is qemu that is consuming the cpu time in some loop effect or if it is another package.
Yesterday I looked at the VMM and the XML configuration files of the VMs and there were unknown to me processor (Skylake-Client-noTSX-IBRS) settings set, but according to my backups were already longer so.
My System: Intel Core i7-9700T
After I have set these to Hypervisor Default, the VMs run error-free again and the CPU Load is in the normal range.